18.00.20 Google DeepMind навчила своїх ботів грати в Quake 3 Arena краще людини | |
 Судячи з усього, в список ігор, першість в яких за останній час машини відібрали у людей, вже можна занести ще одну. Мова про культовий шутер Quake 3 Arena. Компанія Google DeepMind оголосила про створення штучного інтелекту, здатного грати в цю гру не просто як людина, а навіть краще людини. Відразу обмовимося, що мова про режим Capture The Flag (CTF) - захоплення прапора, в якому для перемоги потрібно захопити ворожий прапор і принести на свою «базу».
Як і у випадку з іншими схожими проектами створення ШІ для тієї чи іншої 3D-ігри, головна складність тут полягає в тому, щоб навчити бота орієнтуватися у величезному тривимірному просторі, не маючи точних топографічних даних. Іншими словами, вміти зорієнтуватися на місцевості без карти. Фахівці DeepMind використовували метод навчання з підкріпленням (reinforcement learning), який вже став стандартом в галузі. Аналогічним чином навчалася система AlphaGo і інші алгоритми, які зуміли обіграти людини в декількох відеоіграх Atari. Основне цього методу від класичного машинного навчання полягає в тому, що ШІ навчається в процесі взаємодії з навколишнім середовищем методом проб і помилок, а не на історичних даних. На самому початку навчання бот не має ні найменшого уявлення про саму гру і що в ній потрібно робити. Розібратися у всьому йому потрібно поодинці. Зазвичай одному боту в противники ставлять іншого, і вони починають вчитися. Але DeepMind вирішила піти більш складним шляхом і організувати групові заняття для 30 ботів з метою досягнення більш високого різноманітності стилів гри. Скільки потрібно було зіграти ігор, щоб вийти на прийнятний рівень? Близько 0,5 млн тривалістю по 5 хвилин кожна. Шляхом нескладних підрахунків можна зрозуміти, що навчання зайняло 1736 дні чистого часу. Здавалося б, сама концепція, покладена в основу цього методу, проста як двері, але результат вражає. Боти DeepMind змогли дізнатися не тільки в чому, власне, полягає мета гри, але і самостійно виробили і освоїли різні тактики, які передбачають захист власного прапора, спільні атаки на базу противника і злагоджену командну гру. Важливий момент - кожна нова гра відбувалася на повністю новій, процедурно генеруємій карті. Таким чином, ботів стимулювали до вироблення різних тактик, що підходять до тієї чи іншої карти. На відміну від ботів OpenAI для гри Dota 2, боти DeepMind не мали доступу до числових даних - потокам чисел, які відображають таку інформацію, як відстань між противниками і шкала здоров'я. Замість цього вони вчилися сприймати гру як людина - спостерігаючи тільки за екраном. Але це зовсім не означає, що DeepMind виконала більш трудомістку роботу; Dota 2 куди складніше, ніж урізана версія Quake III, яка використовується в дослідженні DeepMind. 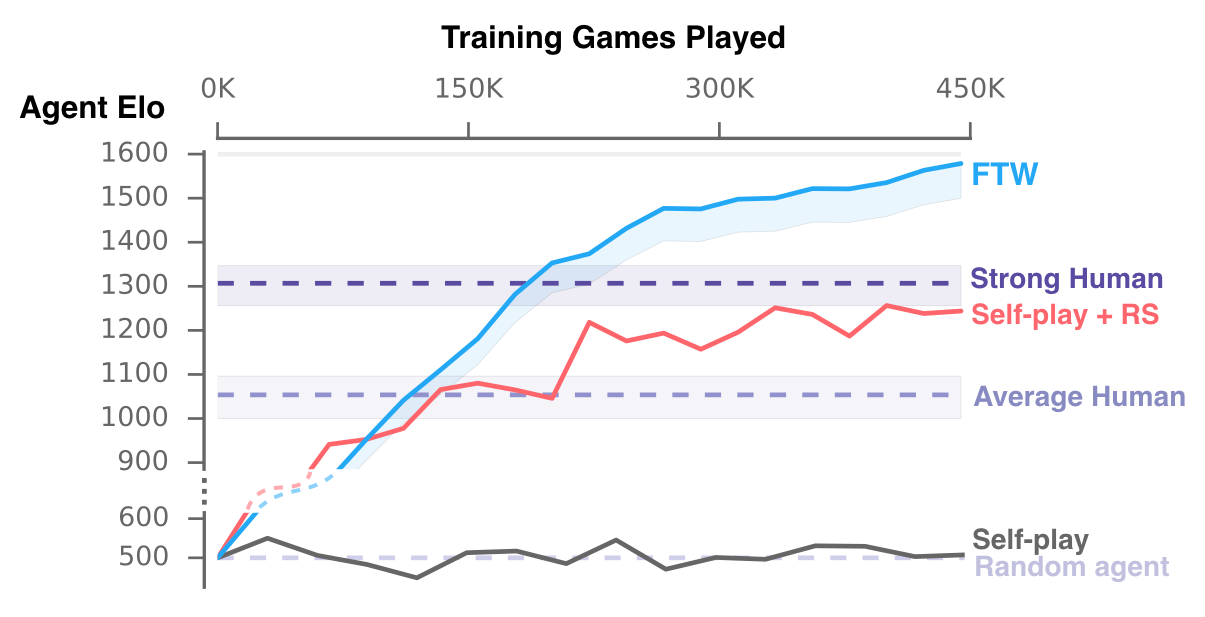 Шкала, що відображає рівень гри різних гравців-людей. FTW - боти DeepMind, які грали один проти одного в команді з 30 гравців.
Для оцінки можливостей ботів фахівці DeepMind організували турнір, в якому команди з двох гравців (обидва бота, обидві людини, бот + чоловік) билися один проти одного. У підсумку найкращий результат показала команда, в якій обидва гравці були ботами. Її оцінка ймовірності виграшу склала 74% проти 43% у середніх гравців і 52% у професійних гравців. Тобто, можна сказати, що комп'ютер більше не поступається людині при грі в Quake III в режимі захоплення прапора. | |
|
| |
| Всього коментарів: 0 | |